What is the significance of Group By clause in an SQL query explain with the help of example With aggregate analytic functions, the OVER clause is appended to the aggregate function call; the function call syntax remains otherwise unchanged. Like their aggregate function counterparts, these analytic functions perform aggregations, but specifically over the relevant window frame for each row. The result data types of these analytic functions are the same as their aggregate function counterparts. Expression_n Expressions that are not encapsulated within an aggregate function and must be included in the GROUP BY Clause at the end of the SQL statement. Aggregate_function This is an aggregate function such as the SUM, COUNT, MIN, MAX, or AVG functions.

Aggregate_expression This is the column or expression that the aggregate_function will be used on. There must be at least one table listed in the FROM clause. These are conditions that must be met for the records to be selected.

The expression used to sort the records in the result set. If more than one expression is provided, the values should be comma separated. ASC sorts the result set in ascending order by expression. DESC sorts the result set in descending order by expression. Though both are used to exclude rows from the result set, you should use the WHERE clause to filter rows before grouping and use the HAVING clause to filter rows after grouping. In other words, WHERE can be used to filter on table columns while HAVING can be used to filter on aggregate functions like count, sum, avg, min, and max.

The presence of HAVING turns a query into a grouped query even if there is no GROUP BY clause. This is the same as what happens when the query contains aggregate functions but no GROUP BY clause. All the selected rows are considered to form a single group, and the SELECT list and HAVING clause can only reference table columns from within aggregate functions. Such a query will emit a single row if the HAVING condition is true, zero rows if it is not true.

There's an additional way to run aggregation over a table. If a query contains table columns only inside aggregate functions, the GROUP BY clause can be omitted, and aggregation by an empty set of keys is assumed. When no rows are selected, aggregate functions will return their initial value. This can occur when filtering results in no matches while aggregating values across an entire table without a grouping, or, when using filtered aggregations within a grouping.

What this value is exactly varies per aggregator, but COUNT, and the various approximate count distinct sketch functions, will always return 0. The UNION operator computes the set union of the rows returned by the involved SELECT statements. A row is in the set union of two result sets if it appears in at least one of the result sets. The two SELECT statements that represent the direct operands of the UNION must produce the same number of columns, and corresponding columns must be of compatible data types.

The value PRECEDING and value FOLLOWING cases are currently only allowed in ROWS mode. They indicate that the frame starts or ends with the row that many rows before or after the current row. Value must be an integer expression not containing any variables, aggregate functions, or window functions.

The value must not be null or negative; but it can be zero, which selects the current row itself. Shapefiles, and other nongeodatabase file-based data sources do not support subqueries. Subqueries that are performed on versioned enterprise feature classes and tables will not return features that are stored in the delta tables. File geodatabases provide the limited support for subqueries explained in this section, while enterprise geodatabases provide full support. For information on the full set of subquery capabilities of enterprise geodatabases, refer to your DBMS documentation.

UNION ALL can be used to query multiple tables at the same time. In this case, it must appear in a subquery in the FROM clause, and the lower-level subqueries that are inputs to the UNION ALL operator must be simple table SELECTs. Features like expressions, column aliasing, JOIN, GROUP BY, ORDER BY, and so on cannot be used. All the expressions in the SELECT, HAVING, and ORDER BY clauses must be calculated based on key expressions or on aggregate functions over non-key expressions . In other words, each column selected from the table must be used either in a key expression or inside an aggregate function, but not both.

A functional dependency exists if the grouped columns are the primary key of the table containing the ungrouped column. Aggregate functions, if any are used, are computed across all rows making up each group, producing a separate value for each group. When a FILTER clause is present, only those rows matching it are included in the input to that aggregate function. The simplest way to get analytic functions is to begin by studying aggregate functions.

An aggregate function collects or gathers data from numerous rows into a unique result row. For instance, users might apply the AVG function to get an average of all the salaries in the EMPLOYEE table. The primary explanation for the FIRST_VALUE analytic function is displayed below. For example, avoid the time sinkhole of forcing SQL Server to check the system/master database every time by using only a stored procedure name, and never prefix it with SP_. Also setting NOCOUNT ON reduces the time required for SQL Server to count rows affected by INSERT, DELETE, and other commands.

Using INNER JOIN with a condition is much faster than using WHERE clauses with conditions. We advise developers to learn SQL server queries to an advanced level for this purpose. For production purposes, these tips may be crucial to adequate performance. Notice that our tutorial examples tend to favor the INNER JOIN. The window frame clause defines the window frame around the current row within a partition, over which the analytic function is evaluated.

Only aggregate analytic functions can use a window frame clause. Function_nameFunction calls can appear in the FROM clause. When the optional WITH ORDINALITY clause is added to the function call, a new column is appended after all the function's output columns with numbering for each row.

In the result set, the order of columns is the same as the order of their specification by the select expressions. If a select expression returns multiple columns, they are ordered the same way they were ordered in the source relation or row type expression. The Group by clause is often used to arrange identical duplicate data into groups with a select statement to group the result-set by one or more columns.

This clause works with the select specific list of items, and we can use HAVING, and ORDER BY clauses. Group by clause always works with an aggregate function like MAX, MIN, SUM, AVG, COUNT. If the WITH TOTALS modifier is specified, another row will be calculated.

This row will have key columns containing default values , and columns of aggregate functions with the values calculated across all the rows (the "total" values). An outer join will combine rows from different tables even if the join condition is not met. Every row in the left table is returned in the result set, and if the join condition is not met, then NULL values are used to fill in the columns from the right table. While the first query is not needed, I've used it to show what it will return. Joins that the native layer can handle directly are translated literally, to a join datasourcewhose left, right, and condition are faithful translations of the original SQL.

In some situations Druid will push down this limit to data servers, which boosts performance. Limits are always pushed down for queries that run with the native Scan or TopN query types. With the native GroupBy query type, it is pushed down when ordering on a column that you are grouping by.

If you notice that adding a limit doesn't change performance very much, then it's possible that Druid wasn't able to push down the limit for your query. The ORDER BY clause refers to columns that are present after execution of GROUP BY. It can be used to order the results based on either grouping expressions or aggregated values. ORDER BY can refer to an expression or a select clause ordinal position .

For non-aggregation queries, ORDER BY can only order by the __time column. For aggregation queries, ORDER BY can order by any column. Using GROUP BY, DISTINCT, or any aggregation functions will trigger an aggregation query using one of Druid's three native aggregation query types.

GROUP BY can refer to an expression or a select clause ordinal position . The SQL standard requires that HAVING must reference only columns in the GROUP BYclause or columns used in aggregate functions. However, MySQL supports an extension to this behavior, and permits HAVING to refer to columns in the SELECT list and columns in outer subqueries as well. In the Group BY clause, the SELECT statement can use constants, aggregate functions, expressions, and column names. The SELECT statement used in the GROUP BY clause can only be used contain column names, aggregate functions, constants and expressions.

The GROUP BY clause is a SQL command that is used to group rows that have the same values. Optionally it is used in conjunction with aggregate functions to produce summary reports from the database. Utilizing a blank OVER clause converts the MIN into an analytic function. In this, the entire result set is interpreted as a single partition. It gives you the minimum salary for all employees and their original data.

For example, the following query is displaying the use of MIN in the Select query. The query_partition_clause breaks the output set into distributions, or collections, of data. The development of the analytic query is limited to the confines forced by these partitions, related to the process a GROUP BY clause modifies the performance of an aggregate function. If the query_partition_clause is eliminated, the entire output collection is interpreted as a separate partition. Using the GROUP BY Clause with the SELECT statement, we can group rows with the same values and aggregate functions, constants, and expressions. It is not permissible to include column names in a SELECT clause that are not referenced in the GROUP BY clause.

The only column names that can be displayed, along with aggregate functions, must be listed in the GROUP BY clause. Since ENAME is not included in the GROUP BYclause, an error message results. You can compose queries using Metabase's graphical interface to join tables, filter and summarize data, create custom columns, and more. And with custom expressions, you can handle the vast majority of analytical use cases, without ever needing to reach for SQL.

The following is the full list of functions supported by file geodatabases, shapefiles, coverages, and other file-based data sources. The functions are also supported by enterprise geodatabases, although these data sources may require different syntax or function names. In addition to the functions below, enterprise geodatabases support other capabilities.

An aggregate function is a function that performs a calculation on a set of values. Most aggregate functions can be used in an analytic function. These aggregate functions are calledaggregate analytic functions. Another difference is that these expressions can contain aggregate function calls, which are not allowed in a regular GROUP BY clause. They are allowed here because windowing occurs after grouping and aggregation.

This syntax allows users to perform analysis that requires aggregation on multiple sets of columns in a single query. Complex grouping operations do not support grouping on expressions composed of input columns. If there is more than one account after dropping nulls, the STDDEV function gives the result of the STDDEV_SAMP.
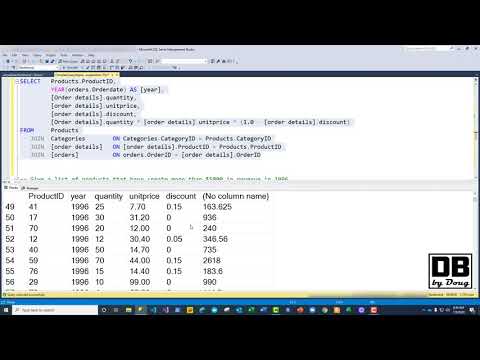
Using an empty OVER clause converts the STDDEV query result into an analytic query. The absence of a partitioning indicates the entire output set is interpreted as a particular partition, so we accept the standard deviation of the salary and the primary data. As aggregate queries, they decrease the number of rows, therefore the expression "aggregate". If the data isn't arranged we convert all the rows in the EMPLOYEE table to a separate row. For example, the following query is displaying the use of all these functions. Using a blank row OVER clause converts the MAX into an analytic function.

The lack of a partitioning clause indicates the entire output set is interpreted as a separate partition. This gives the maximum salary for all employees and their original data. For example, the following query displays the use of MAX in the select query. In this query, all rows in the EMPLOYEE table that have the same department codes are grouped together.

The aggregate function AVG is calculated for the salary column in each group. The department code and the average departmental salary are displayed for each department. When querying multiple tables, use aliases, and employ those aliases in your select statement, so the database doesn't need to parse which column belongs to which table. Note that if you have columns with the same name across multiple tables, you will need to explicitly reference them with either the table name or alias. A GROUP BY statement in SQL specifies that a SQL SELECT statement partitions result rows into groups, based on their values in one or several columns.

Typically, grouping is used to apply some sort of aggregate function for each group. The following is the full list of query operators supported by file geodatabases, shapefiles, coverages, and other file-based data sources. They are also supported by enterprise geodatabases, although these data sources may require different syntax. In addition to the operators below, enterprise geodatabases support other capabilities.





No comments:
Post a Comment
Note: Only a member of this blog may post a comment.